
Create ML Explained: Apple's Toolchain to Build and Train Machine Learning Models
This articles will help you to understand the main features of Create ML and how you can create your own custom machine learning models.


Create ML was introduced as a framework in 2018. In 2019 Apple introduced the dedicated Create ML app that makes building and training Core ML models accessible to everyone with an easy-to-use interface.

With Create ML you can train multiple models with different datasets, organized in a single project, having full control over the training process. You can pause, save, resume, and extend your training process, use external graphic processing units with your Mac for even faster training runs, and preview and test the training outcome directly in the app without any need to use Xcode. You can preview model performance with Continuity, which allows you to use your iPhone camera or microphone on the Mac, or by adding sample data via drag and drop.
Now let's understand what model types are supported by Create ML.
Supported Model Types

Create ML has extended its available model types over the years and supports types for computer vision, sound, and text. You can create models for image classification and object detection as well as style transfer and action classification. Using Motion Sensor data, you can also create activity classification models. Create ML also enables you to classify sounds or text as well as create regression and recommendation models.
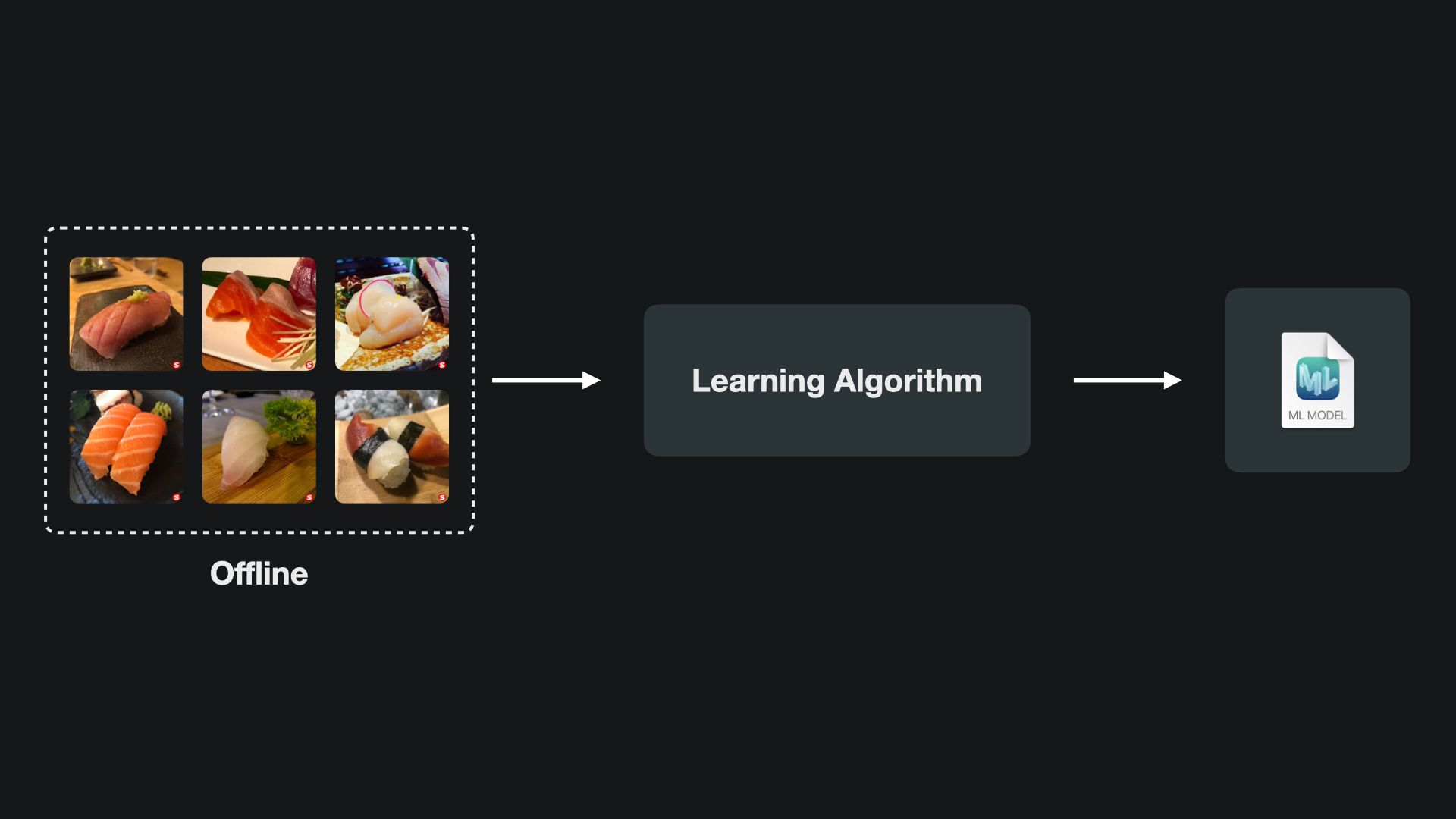
Any training process in Create ML is happening offline with the Create ML application. For training and building a custom machine learning model, any project will require input data that the learning algorithm uses for training the model. The training itself may take a considerable amount of time and will ultimately result in a Core ML model that is ready to be used in Xcode.
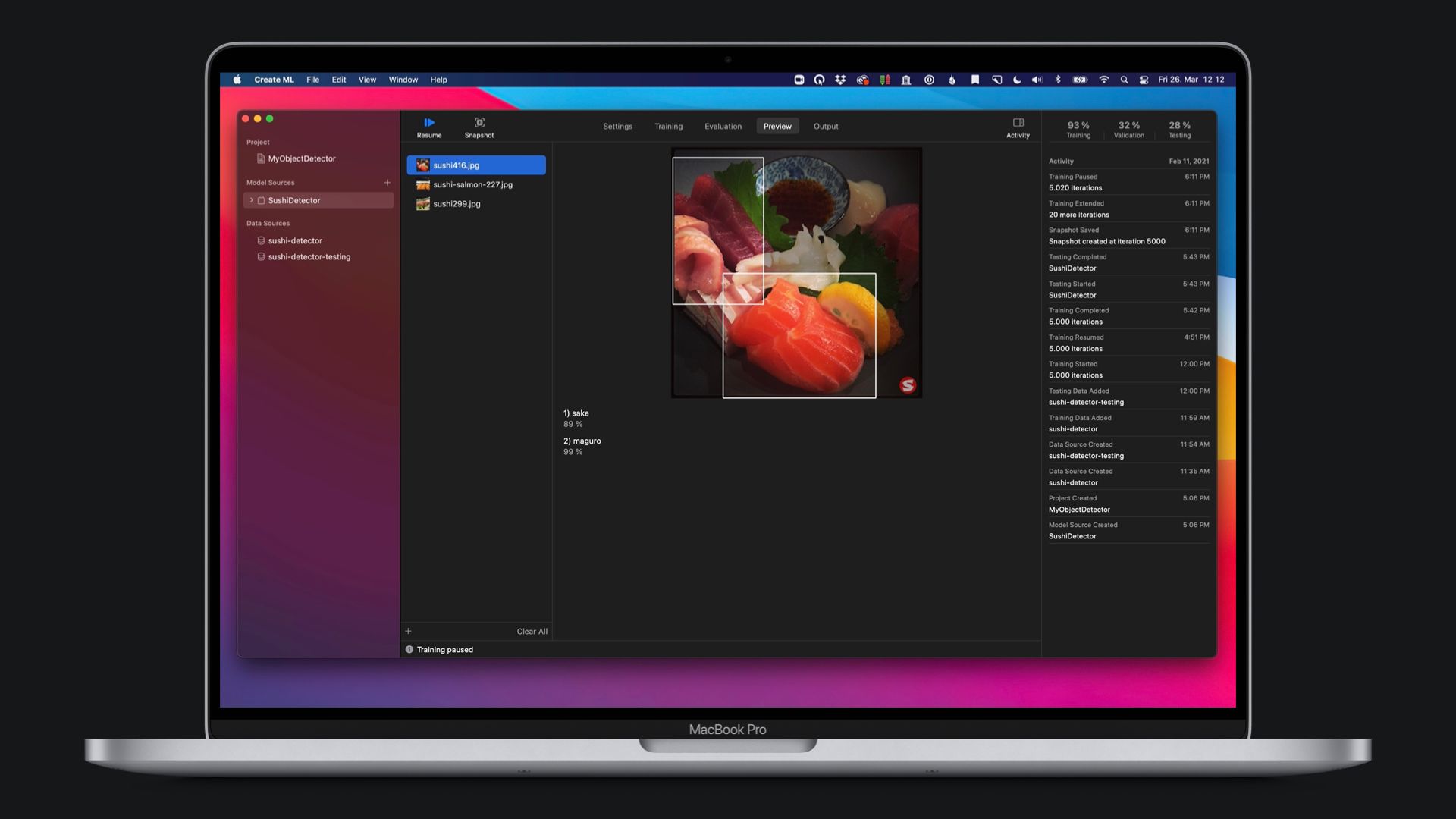
The Create ML App
The Create ML app comes bundled with Xcode. If you download the IDE from developer.apple.com, the entire toolchain is available right away. The easiest way to find it is to use Spotlight and search for Create ML. The user interface itself is simple to understand and focuses on essentials to get you started.
The data can be added via drag and drop and training can be monitored as it happens. Training runs can be paused and resumed and settings from previous trainings can be easily duplicated. Once the training is finished, the model can be evaluated with easy-to-understand graphs and tested ad hoc by either adding sample data via drag and drop, using the Mac's microphone to record audio, or Continuity to use the iPhone camera to add photos or video data.
The resulting Core ML models and their technical specifics can also be reviewed in Create ML before exporting the .mlmodel, sharing the model via email or directly importing the Core ML model into Xcode.
Computer Vision
The most prominent field of machine learning is probably Computer Vision. These are algorithms to gain a high-level understanding of digital images or videos. Apple's high-level framework for computer vision algorithms is conveniently called Vision.
Create ML supports image classification, object detection, action classification and style transfer models in this category. Since it may be a bit too extensive to cover all other models types as well, let's explore these four a bit to see what you need to get started.
The all-time classics of computer vision, algorithms to gain gain high-level understanding from digital images or video, are image classification and object detection. First, let’s see what are the differences between them.
Image Classification
Image classification takes the entire image and uses the machine learning model to make predictions on its content. If the model finds a matching class, it will classify the entire image as the identified class.
So in this case, if the goal is to have a model to detect different types of sushi with an image classification model, the model would classify the left image as sake, which is Japanese for salmon, and the right image as not sake, since it is not salmon. It’s not even sushi at all ;).

Image Classification models are trained by providing datasets of already labeled images. For example, by providing photos of different sushi pieces to recognize sushi types. With as few as 10 images per category, you can reach usable results, but depending on lighting conditions, angles, and resolution, more images may be needed to create a reliable model. The number of images should be balanced across categories and should represent the use case of the model. So if the model should detect sushi types with an iPhone camera in a restaurant with poor lighting, the training data should reflect that and not be produced in a studio with professional lighting and camera equipment.
Object Detection
Object detection models focus on the detection of objects inside areas of an image that can be classified. In the context of a model to detect types of sushi, an object detection machine learning model would detect a sake object inside the left image and assign a box to the area of the object. Everything outside this area would not be sake. As a result, in any image, an object detection model can detect multiple objects. In the right image, the model would detect salmon but also other sushi types, such as tako (octopus), gari (pickled ginger) and wasabi, and so forth.
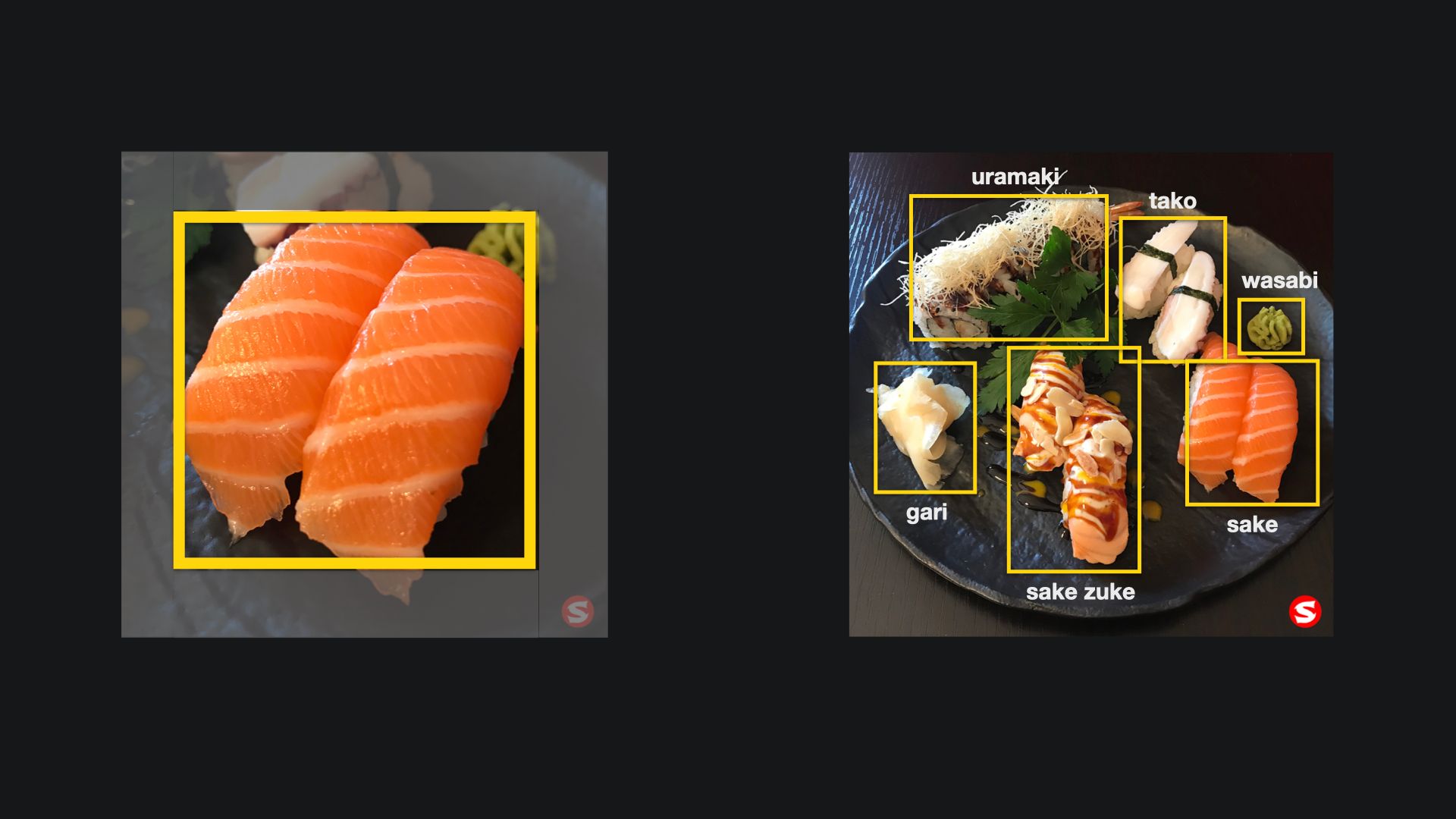
Object Detection models are also trained by providing datasets of already labeled images. In this case, however, the images have to be annotated to define the area of the image the object is located. Also, an image can contain multiple objects, so there may be multiple annotations within one image for the datasets. With as few as 30 images per category, working results can be achieved. However, for a reliable model, the number of necessary images may be considerably higher and should also match the use case of the model, the same as with the Image Classification Model.
Style Transfer
Style transfer models refer to algorithms to manipulate image or video data to adopt the visual style of another image, thus transferring the style. Style transfer algorithms use deep neural networks and provide an exciting way to artistically style imagery in your app or even create new artwork based on existing style.
So if sushi images would stand out even better with a splashy and punchy color pattern, this is what the comic-style sushi images would turn out to be.

It is available in Create ML since 2020 and is very easy to implement. All you need is a reference style or pattern you want to transfer to other images and a set of training data, for which Apple conveniently provides directly within the Create ML app.
Action Classification
Action Classification models use video data to identify body movement's, for example to classify physical exercises like squats or pushups. Similar to Image Classification, it requires sample data of body movements that you want to classify to train the model. It then uses body pose estimation features of the Vision Framework to build the model.

This type of model is not using motion data (e.g. from Apple Watch) for creating the action classification model. For using the motion sensor data, Create ML supports another model type, called Activity Classification.
The process of gathering training videos for an Action Classifier may be a bit more challenging than for Image Classification and Object Detection models and also requires the creation of a negative class of irrelevant actions to build an Action Classifier Data Source so that the model can distinguish types of movements.
Create ML offers much more to be discovered and provides a powerful toolchain to create custom machine-learning models to supercharge your apps with smart features. Explore our other content on Core ML and Create ML if you are curious.
This article is part of a series of articles derived from the presentation Creating Machine Learning Models with Create ML presented as a one time event at the Swift Heroes 2021 Digital Conference on April 16th, 2021.
Where to go next?
If you are interested into knowing more about Core ML, how to use machine learning models in your development projects or how to create custom models you can check our other articles:
- Core ML Explained: Apple's Machine Learning Framework
- Creating annotated data sets with IBM Cloud Annotations
- Creating a Object Detection Machine Learning Model with Create ML
- Using an Object Detection Machine Learning Model in Swift Playgroundsmachine-learning
Recommended Content provided by Apple:
For a deeper dive into the topic of Core ML and Apple's machine learning technologies, you can watch the videos released by Apple on WWDC:
- WWDC 2018 - Introducing Create ML
- WWDC 2019 - Introducing the Create ML App
- WWDC 2020 - Control training in Create ML with Swift
Other Resources:
If you are interested in knowing more about Core ML and how to use machine learning models in your apps, you can go through these resources:
- To understand how to use the Create ML framework to create machine learning models for your app, explore the Apple Developer Documentation.
- To learn more about Apple's approach to machine learning, read about Apple AI chief John Giannandrea's perspective on artificial intelligence and AI strategy.
- To learn about the latest and greatest possibilities in machine learning, explore Apple's research projects on machine learning or even apply to become a Apple Scholar in AI/ML if you are working on cutting-edge fundamental or applied research for your Ph.D.